~AIエージェントによる統計データクレンジングの実践~
本記事は、生成AIとGISを活用した自治体業務の実証シリーズの第5回です。
関連記事
▶ 第1回:自治体GISとAIの融合
▶ 第2回:ArcGIS Onlineと生成AIを連携した人口統計分析の実証
▶ 第3回:生成AIとGISで健康遊具の優先整備地区を抽出してみた
▶第4回:自治体の人材不足はGIS AIで解決できるのか
はじめに
近年、e-Stat APIを利用することで自治体の人口統計を容易に取得できるようになりました。
生成AIやMCPを利用すれば、
・統計データ取得
・CSV出力
・GIS登録
まで自動化することも可能です。
しかし実際に自治体業務で利用しようとすると、単純なAPI連携だけでは解決できない問題が存在します。
今回は和泉市の小地域統計データを用いて、e-Stat APIとGISデータを結合する際に直面した課題を整理します。
和泉市データで発生した問題
まずe-Stat APIから2020年国勢調査データを取得しました。
取得結果は以下の通りです。
- 人口CSV:192件
一方でGIS側の小地域ポリゴンは、
- ポリゴン数:183
- ユニークKEY_CODE:162
でした。
この時点で、
「CSV件数とGIS件数が一致しない」
という問題が発生しました。
単純な属性結合では正しく結合できません。
落とし穴① 町集計と町丁目が混在している
e-Statには、
府中町
だけではなく、
- 府中町一丁目
- 府中町二丁目
- 府中町三丁目
なども同時に存在します。
さらに、
府中町
は
一丁目~八丁目
の合計値となっています。
つまり、
町集計
+
町丁目
をそのままGISへ取り込むと、
人口が二重計上されます。
落とし穴② KEY_CODEが一意ではない
和泉市小地域ポリゴンを確認すると、
KEY_CODE
だけでは一意になっていませんでした。
例えば、
27219101000_E1
27219101000_E2
27219101000_E3
のように、
同じKEY_CODEでも複数ポリゴンが存在します。
落とし穴③ 人口はE1にしか入っていない
統計データを確認すると、
- E1 → 人口あり
- E2 → 0
- E3 → 0
という構造になっていました。
この状態でKEY_CODEだけを使ってJoinすると、
同じ人口が複数ポリゴンへ付与されてしまいます。
結果として人口が重複計上されます。
解決策:JOIN_KEYを作成する
今回採用した方法は、
GIS側
JOIN_KEY
KEY_CODE + “_” + KIGO_E
を作成する方法です。
CSV側も同様に、
join_key
area_code_text + “_” + KIGO_E
を生成します。
その結果、
183ポリゴン
↓
183レコード
で正しく結合できるようになりました。
ArcGIS Pro と CSV 結合で発生する schema.ini の落とし穴
前回の和泉市の分析では、小地域ポリゴンと e-Stat API の人口データでコード体系が一致していなかったため、
KEY_CODE = KCODE_JE + KCODE_E
による JOIN_KEY を作成して結合を行いました。
一方、今回の豊島区データでは、小地域ポリゴンの
area_code
と e-Stat API の
KEY_CODE
が同じコード体系であったため、JOIN_KEY を作成せずに直接結合できる状態でした。
ところが、ここで別の問題が発生しました。
それは ArcGIS Pro が CSV を読み込む際に、コード項目を数値型(Double)として認識してしまうことです。
例えば、
13116001001
という小地域コードは、本来は文字列として扱う必要があります。
しかし ArcGIS Pro は CSV を自動判定するため、
小地域ポリゴン
area_code(Text)
人口CSV
KEY_CODE(Double)
という状態になることがあります。
この場合、値は同じでも型が異なるため Join が実行できません。
そこで利用するのが schema.ini です。
CSV と同じフォルダに schema.ini を配置し、
[toshima_demographics_2020.csv]
Format=CSVDelimited
ColNameHeader=True
Col1=municipality_name Text Width 50
Col2=year Long
Col3=KEY_CODE Text Width 20
Col4=area_name Text Width 50
Col5=population_total Long
のように定義します。
重要なのは、
Col3=KEY_CODE Text Width 20
です。
これにより ArcGIS Pro は KEY_CODE を文字列として読み込みます。
結果として、
area_code (Text)
=
KEY_CODE (Text)
となり、正常に Join できるようになります。
なお、インターネット上では
CharacterSet=65001
を記載している例もありますが、ArcGIS Pro では
schema.ini に値が無効なオプションがあります
CharacterSet=65001
というエラーが発生することがあります。
そのため UTF-8 の CSV を利用する場合でも、CharacterSet の指定は行わず、必要なフィールド定義のみを記述する方が安全です。
今回のように自治体によって、
- JOIN_KEY の作成が必要なケース(和泉市)
- KEY_CODE をそのまま利用できるケース(豊島区)
があります。
ただし、どちらの場合でも ArcGIS Pro 上では「文字列として結合できる状態にする」ことが重要であり、そのための手段として schema.ini が有効です。
MCP化して分かったこと
今回の検証で分かったのは、
e-Stat APIが利用できること
と
自治体業務で使えるGISデータになること
は全く別問題だということです。
実際には、
- 統計構造の理解
- 秘匿処理の理解
- 小地域コードの理解
- GIS側データ構造の理解
が必要になります。
今回作成したMCPでは、
- 総人口
- 0~14歳人口
- 65歳以上人口
- CSV出力
- GIS結合用JOIN_KEY生成
まで自動化しています。
AIにe-Stat APIを読ませても実務データにはならない
生成AIはe-Stat APIを利用できます。
しかし、
APIが返したデータ
=
実務で利用できるGISデータ
ではありません。
今回の検証では、
豊島区では問題なく動いた処理が、
和泉市では正しく動きませんでした。
原因を追跡すると、
KEY_CODE
↓
KIGO_E
↓
秘匿処理
↓
JOIN_KEY
という統計構造の違いにたどり着きました。
つまり、
AIがデータを取得できること
と
自治体業務で利用できること
の間には大きな差があります。
次のステップは「年齢階級」の細分化
現在のMCPでは、
- 総人口
- 0~14歳人口
- 65歳以上人口
を取得しています。
しかし遊具配置を考える場合、
本当に必要なのは
0~14歳
ではありません。
例えば、
- 幼児用すべり台
- 幼児用ブランコ
- スプリング遊具
- 砂場
- おむつ替え設備
などは、
主に0~4歳児を対象としています。
そのため次の段階では、
- 0~4歳人口
- 5~9歳人口
- 10~14歳人口
を取得し、
より実態に即した分析を行う予定です。
今後想定される分析の方向性
今回の検証では、小地域単位で人口統計をGISへ結合できることを確認しました。
今後、公園ごとの遊具配置情報や遊具台帳などのデータが利用できれば、人口統計と組み合わせた分析も可能になります。
例えば、
小地域人口
+
遊具配置情報
を組み合わせることで、
0~4歳人口100人あたりの幼児向け遊具数
といった指標を作成できる可能性があります。
また、
幼児遊具不足指数
=
0~4歳人口
÷
幼児向け遊具数
のような考え方により、
子育て世代が多い地域と遊具配置状況との関係を可視化できる可能性があります。
現在は構想段階ですが、人口統計と公園施設データを組み合わせることで、公園整備や子育て支援施策の検討材料として活用できる可能性があると考えています。
本手法はe-Stat APIを活用しているため、和泉市に限らず他自治体へも適用可能です。
今後は、実際の施設データと組み合わせながら、GISと統計データを活用した政策検討支援についても研究を進めていきたいと考えています。
AIエージェントによるデータ整備という視点
今回の検証は、単にe-Stat APIから人口データを取得したという話ではありません。
実際には、
e-Stat API
↓
統計コードの確認
↓
KEY_CODEの確認
↓
KIGO_Eの確認
↓
秘匿化構造の確認
↓
JOIN_KEY生成
↓
CSV出力
↓
ArcGIS結合
という複数の工程を経ています。
表面的には「人口マップを作成した」ように見えますが、実際に時間を要したのは統計構造の理解とデータ整備でした。
和泉市のケースでは、
・人口CSV:192レコード
・小地域ポリゴン:183ポリゴン
・ユニークKEY_CODE:162件
という状態であり、単純なJoinでは正しく結合できませんでした。
そのため、
・町集計と町丁目の重複確認
・KEY_CODEとKIGO_Eの関係確認
・秘匿化データの確認
・GIS側との整合確認
を行い、最終的にJOIN_KEYを生成することで正しい結合を実現しました。
従来であれば、このような作業は統計担当者やGIS担当者が手作業で調査しながら進める必要がありました。
今回の検証では、生成AIとMCPを活用することで、こうしたデータ整備作業を支援できる可能性を確認しています。
近年は、
オープンデータ
↓
AIエージェント
↓
データクレンジング
↓
GIS分析
↓
意思決定
という流れが重要になりつつあります。
単に地図を作成するだけではなく、分析に利用できるデータ基盤を整備すること自体が価値となる時代へ変化しています。
今回の成果は、e-Stat APIを利用した人口データ取得だけではありません。
統計データを自治体GISで利用できる形へ変換するための知識とノウハウを整理できたことに、大きな意義があると考えています。
まとめ
今回の検証は単なるMCP開発ではありません。
統計データを取得するだけではなく、
自治体GISで利用できる形へ変換するための知識を整理するプロセスでした。
e-Stat APIや生成AIが普及しても、
統計構造やGISデータ構造を理解することの重要性は変わりません。
むしろGIS AI時代だからこそ、
「データを取得する技術」
ではなく、
「実務で使えるデータへ変換する知識」
がますます重要になると考えています。
MCPで取得した人口データを用いた試験分析
今回整備したデータを用いて、
- クラスター・外れ値分析
- 最適化ホットスポット分析
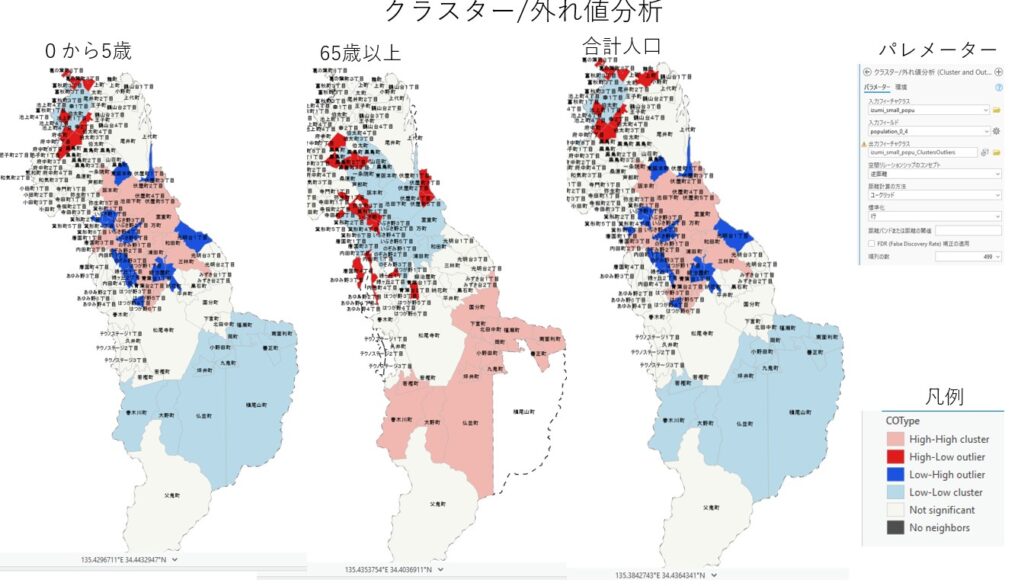
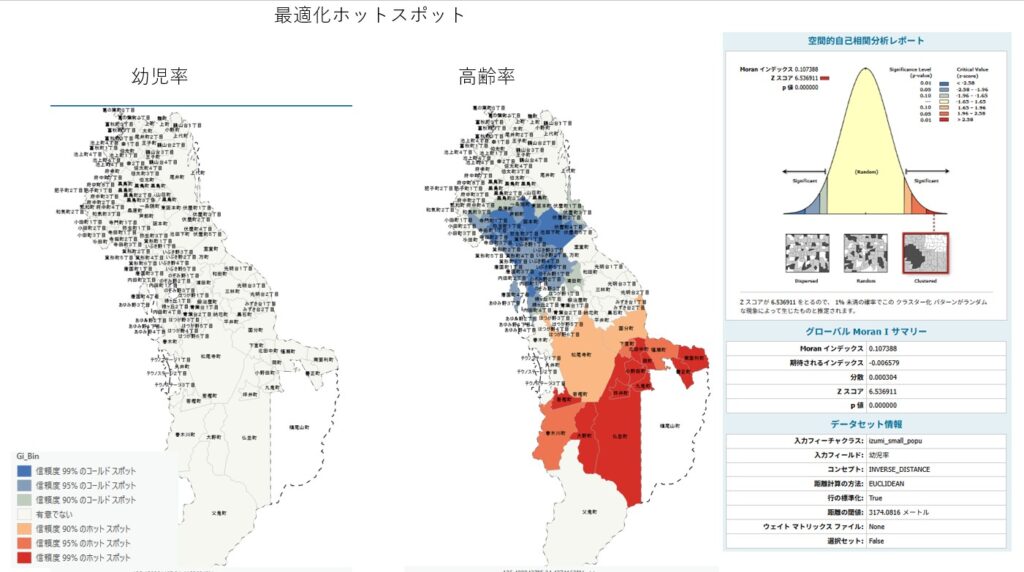
を実施しました。
その結果、
65歳以上人口については有意な空間集積が確認された一方、
幼児人口については明確な集積は確認されませんでした。
これは統計データをGISへ正しく結合できたことで初めて実施できる分析であり、今後は公園施設データや遊具配置データと組み合わせることで、より実践的な政策検討へ発展できる可能性があります。
関連記事
▶ 第1回:自治体GISとAIの融合
▶ 第2回:ArcGIS Onlineと生成AIを連携した人口統計分析の実証
▶ 第3回:生成AIとGISで健康遊具の優先整備地区を抽出してみた
▶第4回:自治体の人材不足はGIS AIで解決できるのか
コメントを残す